ETL and Dagster
One of Dagster’s core strengths is breaking down data pipelines to their individual assets. This provides full lineage and visibility between different systems.
When visualizing your data stack, it’s often helpful to think of data flowing from left to right. On the far left, you typically find your raw data sources and the ETL processes that bring that data into your platform. This is a logical starting point for building out a data platform: focusing on ETL assets helps you concentrate on the most important datasets and avoid duplicating effort.
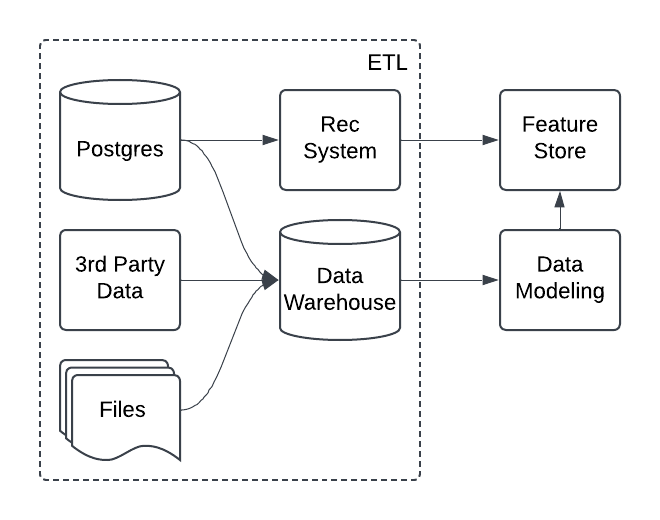
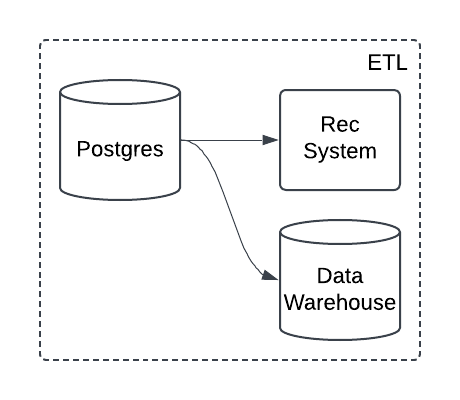
This asset based approach is what makes Dagster particularly well-suited for managing ETL pipelines. Because source assets are so fundamental to building with data, they tend to be reused across multiple projects. For example, if you're ingesting data from an application database, that data may feed into both analytics dashboards and machine learning workflows.
Without an asset based approach, it can get lost that multiple processes rely on the same sources.
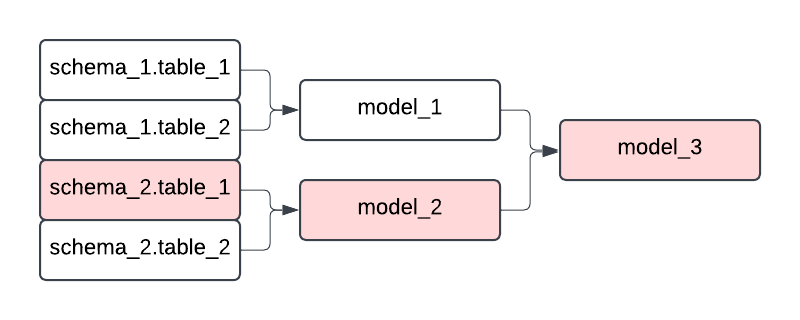
Source asset granularity
Another reason an asset based approach tends to work well for ETL is that data sources tend to represent multiple individual entities. Consider a pipeline that ingests data from your application database, you're likely pulling in multiple schema or tables, each used by specific data applications.
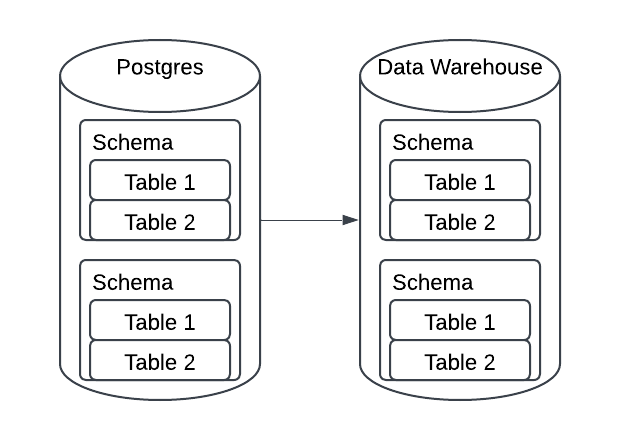
Each of these entities should be tracked as its own asset, so you can associate downstream processes with each one individually. That granularity gives you the ability to monitor, reason about, and recover from failures more effectively.
For example, if one source table fails to ingest, an asset based approach allows you to quickly understand which downstream assets and applications are impacted. This level of observability and control is what makes asset-based orchestration so powerful, especially in the context of managing critical ETL pipelines.