ETL with APIs
The NASAResource gives us the ability to extract data, but it leaves us in a slightly more ambiguous position than when we were importing static files. With files, there’s a clear boundary. One file ends, another begins. When extracting data from an API, those boundaries aren’t always as obvious, making it less clear how to structure our assets.
Time bounding
With the NASA API and our resource, we need to provide a date range when pulling data. Some APIs allow filtering down to the minute or even the second, but the NASA API works at the day level. This makes it easy to structure our ingestion around pulling a full day's worth of data at a time.
But we do have the question of when should we run the process? If we try to fetch today's data, we can't be sure that all of it has been published yet. The safest approach is to query the API for the previous day’s data by using a rolling, non-overlapping window.
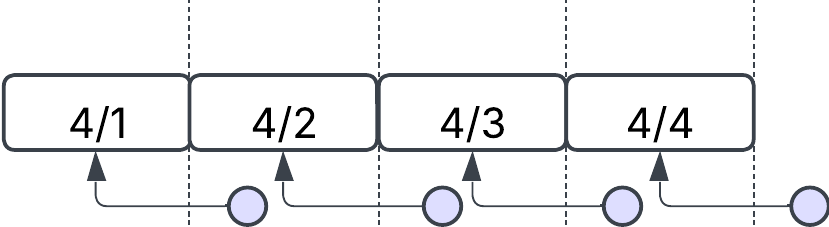
Alternatively, it’s possible to implement a rolling window with overlaps:
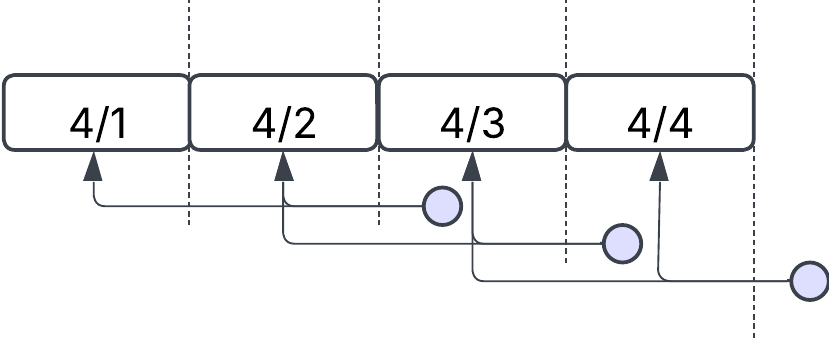
This can be useful in two key scenarios:
- When the API allows for data corrections or updates, such as changes to past orders or late-arriving data.
- To add resiliency in the event of failures. If one run fails, the next overlapping window might successfully capture the missed data.
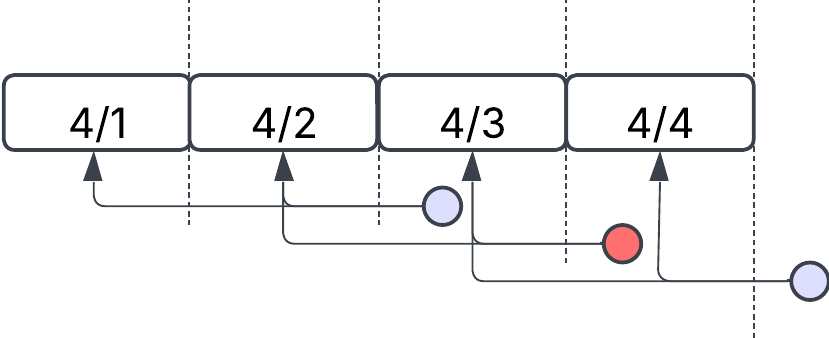
Rolling windows with overlaps do introduce added complexity. Since overlapping periods will process the same data more than once, this needs to be handled at the destination layer. This can be done using:
- Hard deletes, where old overlapping data is removed before new data is loaded.
- Soft deletes, where older records are marked as outdated and superseded by the newer ones.
For the purposes of this course, we’ll stick to rolling windows without overlaps, which provide a simpler and more deterministic ingestion model.